 Tutorials
Tutorials Intermediate
Semantic Caching for LLMs: Cut Your Token Bill in Python
Build a semantic cache that reuses answers for similar prompts and slashes LLM API costs.
10 min read·Kodetra Technologies
TodayHow-to content for builders, indie hackers, and AI engineers. Less theory, more shipped code.
Tutorials Build a semantic cache that reuses answers for similar prompts and slashes LLM API costs.
 Tutorials
Tutorials Use GPT-5.6 Sol's new max reasoning effort and ultra subagents via the Responses API.
 Tutorials
Tutorials Embed Copilot's agent runtime and route work to scoped sub-agents, with runnable Python.
 Tutorials
Tutorials A runnable Python governor that caps LLM spend per user and auto-downgrades models.
 Tutorials
Tutorials Stream Gemini's thought summaries live, control reasoning effort, and track thinking-token cost.
 Tutorials
Tutorials Build a browser-control agent with Gemini 3.5 Flash's new computer_use tool and Playwright.
 Tutorials
Tutorials Surface, stream, and log Gemini 2.5 Pro Deep Think's reasoning chain with thought summaries.
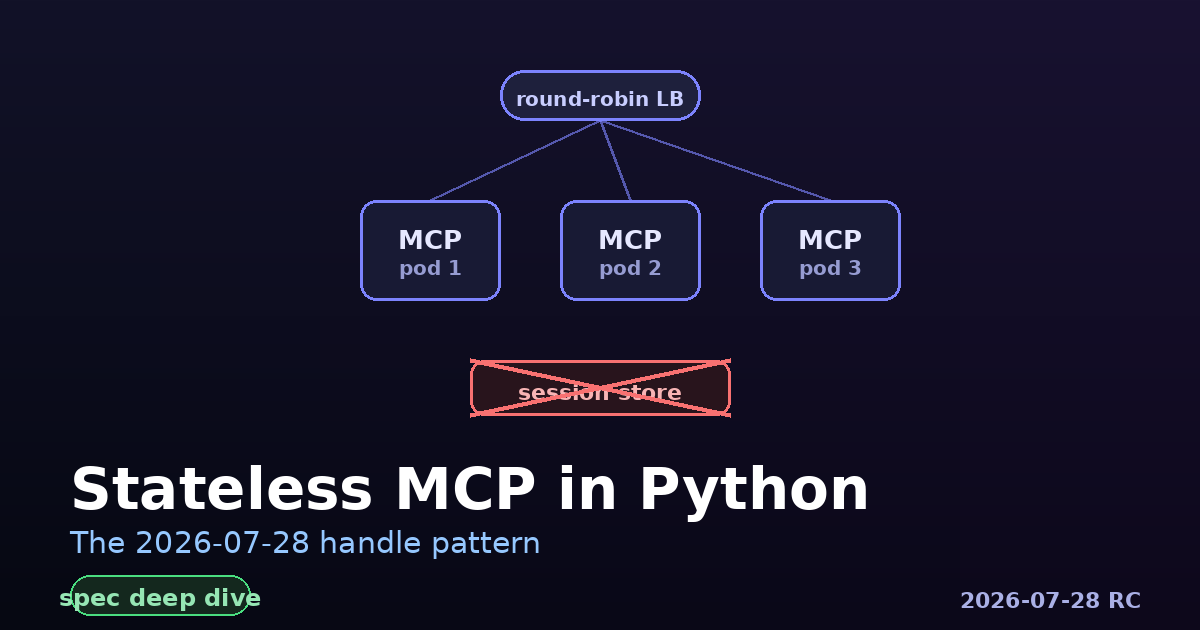 Tutorials
Tutorials Port your MCP server to the stateless 2026-07-28 spec using the explicit-handle pattern.
 Tutorials
Tutorials Build a skill-manifest registry so an AI agent wields dozens of skills without context bloat.
 Tutorials
Tutorials Build a frugal tool-calling coding agent on NVIDIA's open Nemotron 3 Nano via OpenRouter in Python.
 Tutorials
Tutorials Build agents with typed deps, validated output, and offline tests using Pydantic AI.
 Tutorials
Tutorials Build a Python trust-boundary firewall that stops prompt-injection attacks on your AI coding agent.