🛠️Sebastian Raschka's Workflow for Reading LLM Architectures
TL;DR
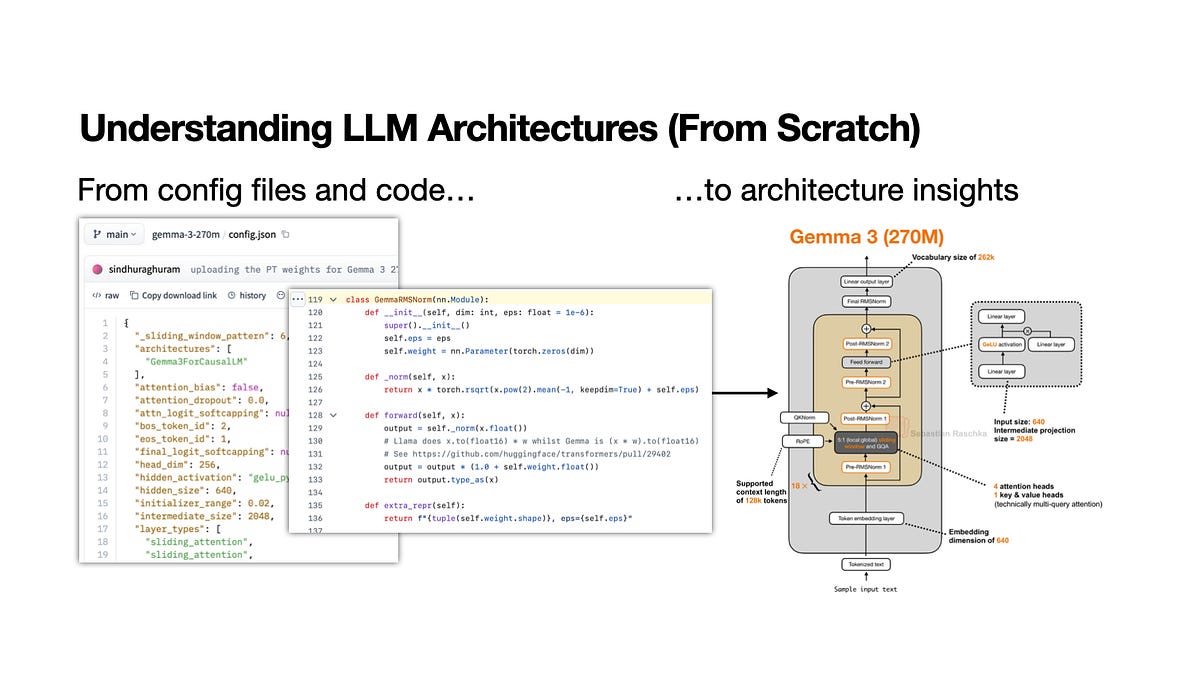
Sebastian Raschka walks through the exact process he uses to dissect a new LLM architecture. He starts from the config and maps attention and normalization choices, a repeatable method for engineers who want to read model code without drowning.
Sebastian Raschka walks through the exact process he uses to dissect a new LLM architecture. He starts from the config and maps attention and normalization choices, a repeatable method for engineers who want to read model code without drowning.
Key Points
Lays out a step-by-step method for decoding an unfamiliar model architecture
Covers where to look first: config, attention variant, normalization, and tokenizer
Ties recent design trends like KV sharing and compressed attention to real models
Written by the author of 'Build a Large Language Model (From Scratch)'
Why It Matters
Engineers who can quickly read a new architecture instead of waiting for a blog summary make faster build-versus-adopt calls as model releases accelerate.
Quick Facts
Frequently Asked Questions
Why does this matter?
Engineers who can quickly read a new architecture instead of waiting for a blog summary make faster build-versus-adopt calls as model releases accelerate.
What happened?
Sebastian Raschka walks through the exact process he uses to dissect a new LLM architecture. He starts from the config and maps attention and normalization choices, a repeatable method for engineers who want to read model code without drowning.
Comments
Be the first to comment
Enjoyed this article?
Get it daily. 7am. Free. Reads in 5 minutes.