Vocera
What is Vocera?
End-to-end testing and observability for Voice AI and Chat AI agents. Simulate scenarios, monitor production, and catch issues before they go live.
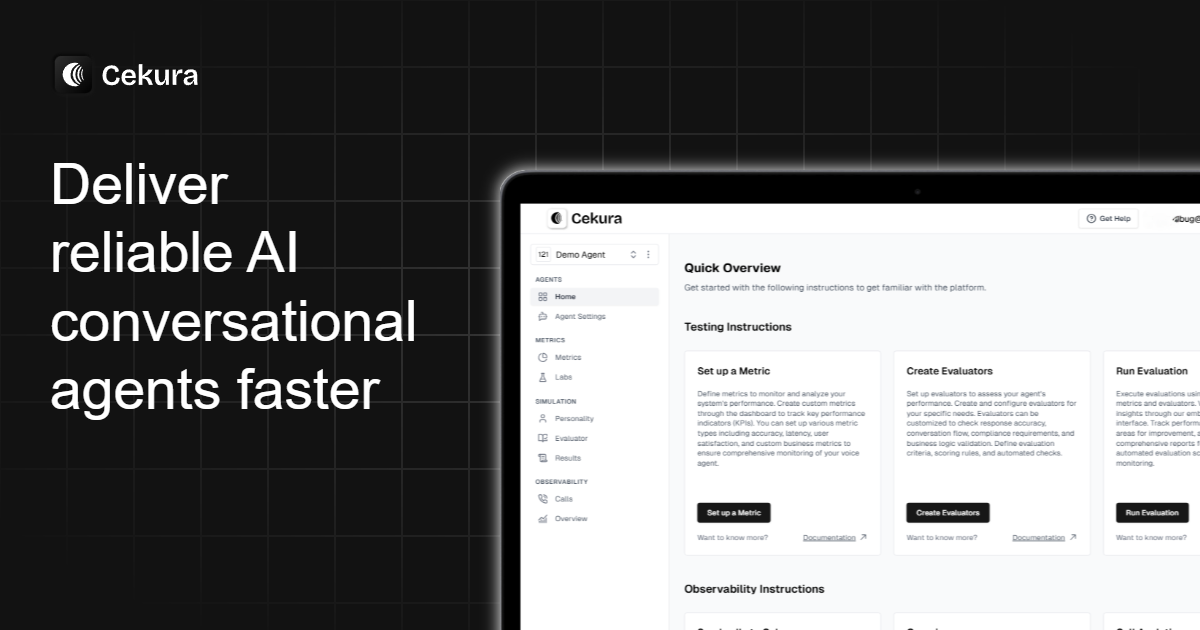
Cekura is an end-to-end testing and observability platform for conversational AI agents, including voice and chat. It enables teams to run pre-production simulations across diverse personas, monitor production conversations in real time, and evaluate key quality metrics like empathy, responsiveness, and hallucination. The platform integrates with popular voice AI frameworks such as Vapi, Retell, and ElevenLabs, and supports custom scenario creation, parallel testing, and alerting. Cekura helps ensure reliable, high-quality conversational experiences before deployment.
Key Features
Use Cases
Opens in a new tab on Vocera website.
Frequently Asked Questions
What does Vocera do?
End-to-end testing and observability for Voice AI and Chat AI agents. Simulate scenarios, monitor production, and catch issues before they go live.
Comments
Be the first to comment
Discover more AI tools like this
Get the best AI tools, news, and resources delivered weekly.
Join 2,035 builders reading daily.