 Tutorials
Tutorials Intermediate
Build an LLM Spend Governor: Budget Caps in Python
A runnable Python governor that caps LLM spend per user and auto-downgrades models.
10 min read·Kodetra Technologies
YesterdayHow-to content for builders, indie hackers, and AI engineers. Less theory, more shipped code.
Tutorials A runnable Python governor that caps LLM spend per user and auto-downgrades models.
 Tutorials
Tutorials Cut MCP agent context up to 99% by exposing tools as a code API the model calls in code.
 Tutorials
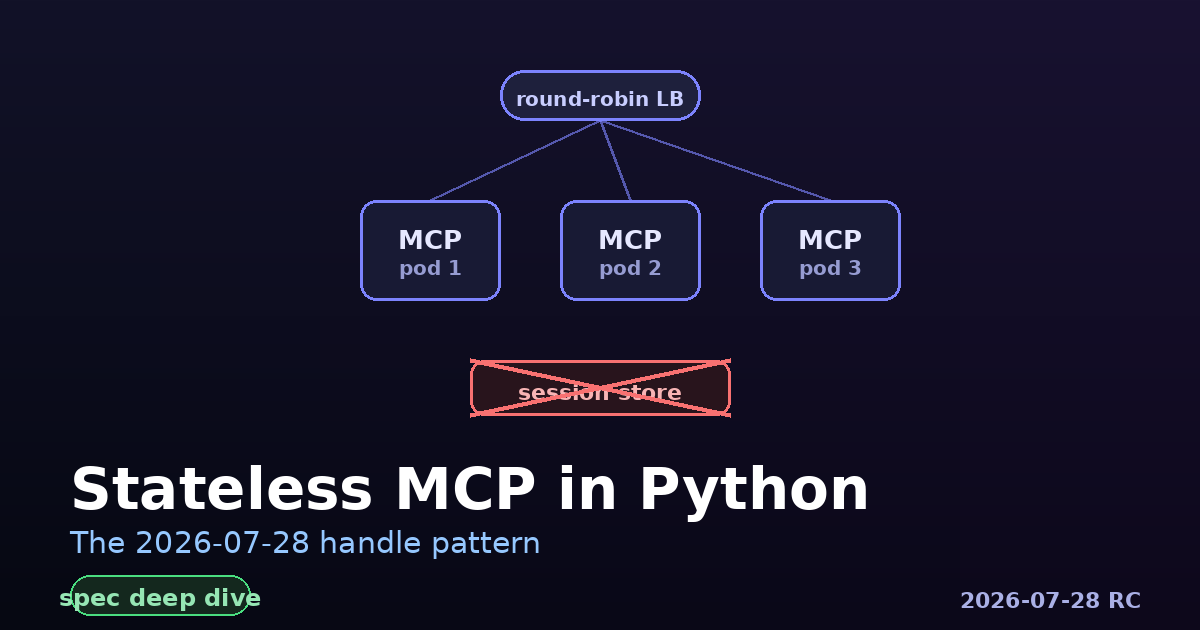
Tutorials Port your MCP server to the stateless 2026-07-28 spec using the explicit-handle pattern.
 Tutorials
Tutorials Build a skill-manifest registry so an AI agent wields dozens of skills without context bloat.
 Tutorials
Tutorials Build a plan-act-verify agent loop with an external check, retry budget, and clear stop rules.
 Tutorials
Tutorials Reuse a huge codebase prefix across every Fable 5 call and pay ~90% less.
 Tutorials
Tutorials Use DeepSeek V4 Pro's auto KV cache to run huge-context jobs for cents.
 Tutorials
Tutorials MiniMax M3 hands-on: MSA sparse attention plus real 1M-token long context, with runnable Python.
 Tutorials
Tutorials Point the Anthropic SDK at Qwen 3.7 Max with one base-URL change: 1M context, thinking, caching.
 Tutorials
Tutorials Build a standard MCP server in Python that plugs into Gemini Spark and Claude Desktop.
 Tutorials
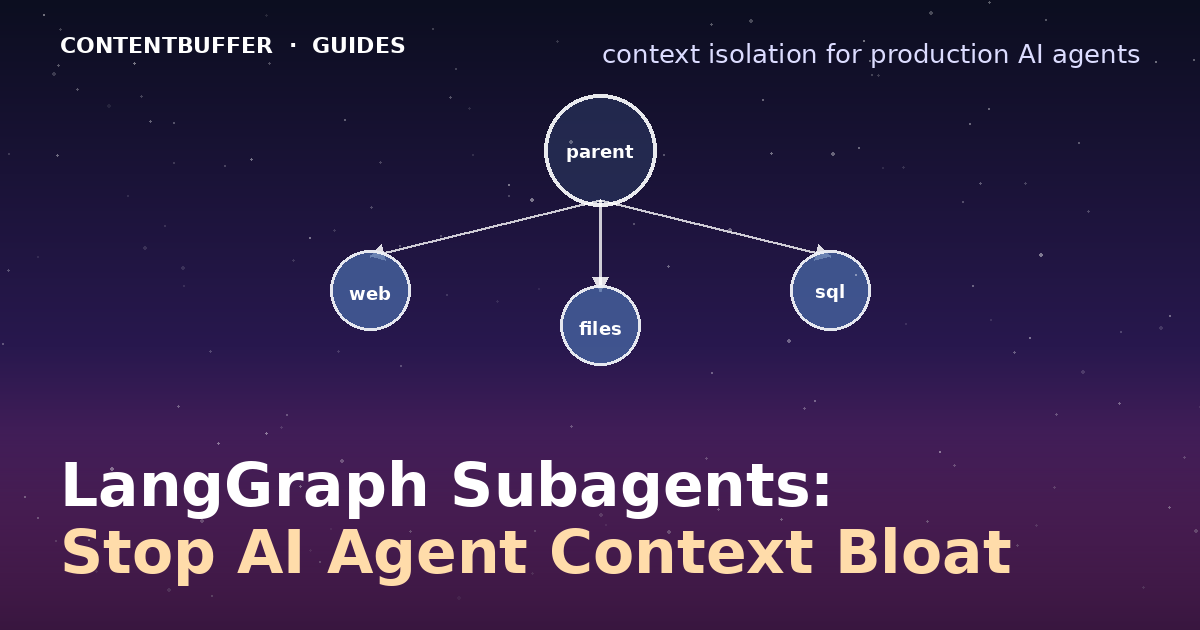
Tutorials Use LangGraph v0.4 subagents to isolate tool noise and keep main agent context clean.
Tutorials Use LangGraph v0.4 subagents to isolate tool noise and keep main agent context clean.