Saga Pattern: Distributed Transactions Without 2PC
Summary
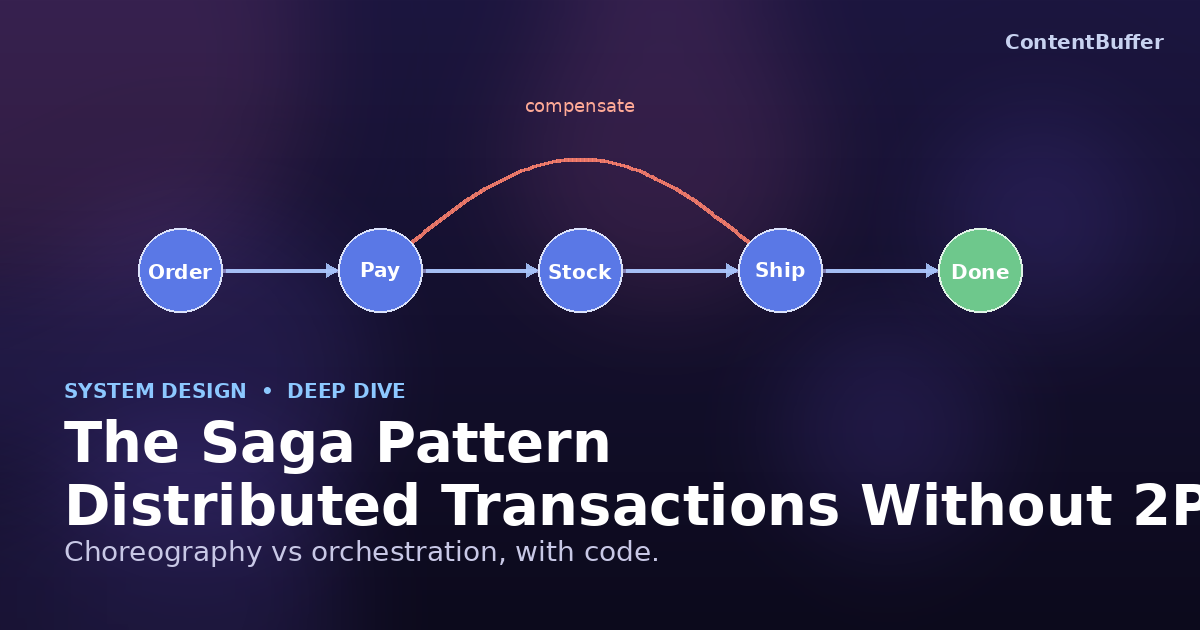
Coordinate multi-service writes with orchestration, choreography, and compensating transactions.
If you have ever shipped a feature that touches three services in one user action — charge a card, decrement inventory, send a confirmation email — you have run head-first into the dirty secret of microservices: the database transaction stops at the service boundary. Two-phase commit (2PC) used to paper over that gap, but in 2026 it is effectively dead in cloud-native stacks. It locks resources across services, falls over when any participant is slow, and is unsupported by the message brokers and managed databases most teams build on.
The saga pattern is the answer that survived. Instead of one global transaction, a saga is a sequence of local transactions, each in its own service, glued together with events or commands. When a step fails, the saga runs compensating transactions that semantically undo the earlier steps. No global locks, no XA driver, no coordinator that has to stay up for the entire workflow.
Keep reading — it's free
Enter your email to keep reading — plus the best of AI & tech, daily. Free, forever.
Already a member? Sign in
Comments
Be the first to comment